Introduction
In this post, I explain the RoPE (Rotary Position Embedding) implementation mathematically. I assume readers have some high-level understanding of sinusoidal positional encoding and Rotary PE.
The implementation discussed here is based on HuggingFace’s Transformers library (specifically the Llama model).
RoPE was introduced in the paper “RoFormer: Enhanced Transformer with Rotary Position Embedding” by Su et al. (2021). The core idea is to encode positional information by rotating query and key vectors before computing attention scores — rather than adding a fixed positional vector to token embeddings. This results in an elegant property: attention scores naturally encode relative position between tokens.
RoPE Implementation in the Llama Model
Note: Some code has been removed for readability.
class LlamaRotaryEmbedding(torch.nn.Module):
inv_freq: torch.Tensor
def __init__(self, config, device=None):
super().__init__()
self.config = config
base = self.config.base_theta
dim = self.config.hidden_size
num_heads = self.config.num_attn_heads
head_dim = dim // num_heads
inv_freq = 1.0 / (
base ** (
torch.arange(0, dim, 2, dtype=torch.int64) / head_dim)
)
self.register_buffer("inv_freq", inv_freq, persistent=False)
self.register_buffer("original_inv_freq", inv_freq.clone(), persistent=False)
@torch.no_grad()
def forward(self, x, position_ids):
inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1).to(x.device)
position_ids_expanded = position_ids[:, None, :].float()
device_type = x.device.type if isinstance(x.device.type, str) and x.device.type != "mps" else "cpu"
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
emb = torch.cat((freqs, freqs), dim=-1)
cos = emb.cos() * self.attention_scaling
sin = emb.sin() * self.attention_scaling
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q, k, cos, sin, unsqueeze_dim=1):
cos = cos.unsqueeze(unsqueeze_dim)
sin = sin.unsqueeze(unsqueeze_dim)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
Simplified Version
def simple_rope():
sq_len = 100
base_theta = 10000
head_dim = 64
q = torch.randn(size=(sq_len, head_dim))
k = torch.randn(size=(sq_len, head_dim))
inv_freq = 1.0 / (base_theta ** (torch.arange(0, head_dim, 2, dtype=torch.int64) / head_dim))
position_ids = torch.arange(0, sq_len)
freq = torch.outer(position_ids, inv_freq)
cos = torch.cat([freq.cos(), freq.cos()], dim=-1)
sin = torch.cat([freq.sin(), freq.sin()], dim=-1)
# Applying the rotation
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
q_embed, k_embed = simple_rope()
Explanation
In the code above, we rotate the query and key vectors using sinusoidal functions:
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
This is equivalent to applying a rotation matrix to each query and key vector:
$$ q' = R(m)\, q \qquad k' = R(n)\, k $$where $m$ and $n$ are the position indices of the query and key tokens respectively, and $R(\theta)$ is the 2D rotation matrix:
$$ R(\theta) = \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} $$For a 2D vector $\begin{bmatrix}x \\ y\end{bmatrix}$, rotation gives:
$$ R(\theta) \begin{bmatrix} x \\ y \end{bmatrix} =\begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} =\begin{bmatrix} x\cos\theta - y\sin\theta \\ x\sin\theta + y\cos\theta \end{bmatrix} $$$$ x' = x\cos\theta - y\sin\theta $$$$ y' = x\sin\theta + y\cos\theta $$Key Property: Relative Position in Attention
We rotate query and key independently. The relative rotation naturally emerges during the attention dot product:
This holds because:
$$ R(m)^T = R(-m) $$$$ R(m)^T R(n) = R(-m)\, R(n) = R(n - m) $$This is the most elegant property of RoPE. The attention score between a query at position $m$ and a key at position $n$ depends only on the relative distance $(n - m)$, not on their absolute positions. This gives the model an inherent sense of relative position without needing a separate relative positional encoding scheme.
Relative Position Matrix in Attention
The relative position $(m - n)$ across all query-key pairs in a sequence of length 9 looks like:
$$ \begin{bmatrix} 0 & -1 & -2 & -3 & -4 & -5 & -6 & -7 & -8 \\ 1 & 0 & -1 & -2 & -3 & -4 & -5 & -6 & -7 \\ 2 & 1 & 0 & -1 & -2 & -3 & -4 & -5 & -6 \\ 3 & 2 & 1 & 0 & -1 & -2 & -3 & -4 & -5 \\ 4 & 3 & 2 & 1 & 0 & -1 & -2 & -3 & -4 \\ 5 & 4 & 3 & 2 & 1 & 0 & -1 & -2 & -3 \\ 6 & 5 & 4 & 3 & 2 & 1 & 0 & -1 & -2 \\ 7 & 6 & 5 & 4 & 3 & 2 & 1 & 0 & -1 \\ 8 & 7 & 6 & 5 & 4 & 3 & 2 & 1 & 0 \end{bmatrix} $$Step-by-Step Walkthrough
Token Representation
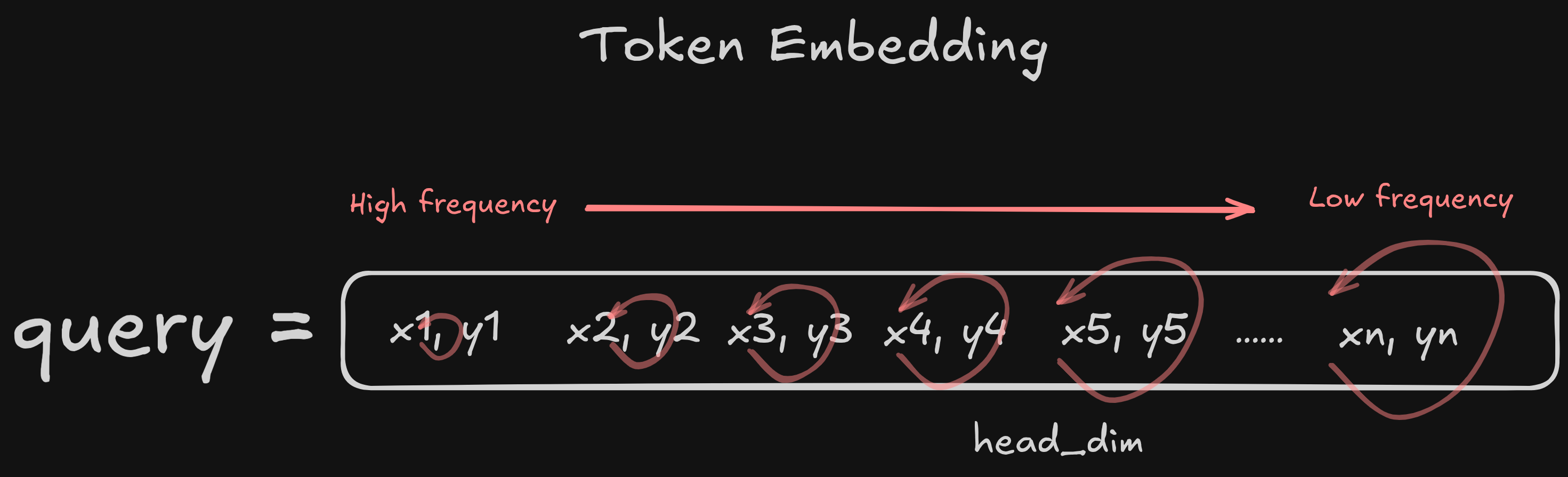
Before diving into the steps, it helps to understand how a token embedding is laid out in memory. For a token with head_dim = 6, the embedding is arranged as:
A vector of length $d$ has $d/2$ planes, where each plane is an $(x_i, y_i)$ pair that will be rotated together:
$$ \text{planes} = [x_1, y_1],\; [x_2, y_2],\; [x_3, y_3],\; \ldots,\; [x_{d/2}, y_{d/2}] $$In the HuggingFace RoPE implementation, the embedding is arranged as $[x_1, x_2, \ldots, x_{d/2},\; y_1, y_2, \ldots, y_{d/2}]$ — all $x$-values first, then all $y$-values (non-interleaved layout). The rotate_half function is specifically designed for this layout. An alternative layout places pairs together: $[x_1, y_1, x_2, y_2, \ldots]$ (interleaved), but this implementation uses the former.
Step 1: Inverse Frequency
inv_freq = 1.0 / (base_theta ** (torch.arange(0, head_dim, 2, dtype=torch.int64) / head_dim))
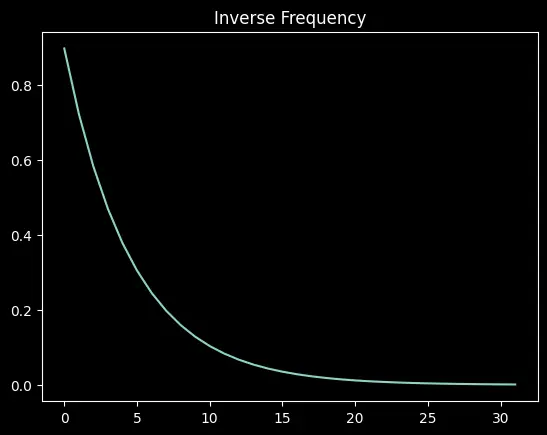
What is inverse frequency?
Inverse frequency controls the rotation speed for each plane in the token embedding. The early planes (low index $i$) have higher inverse frequency values and rotate faster — more per unit of position. The later planes have lower values and rotate slowly.
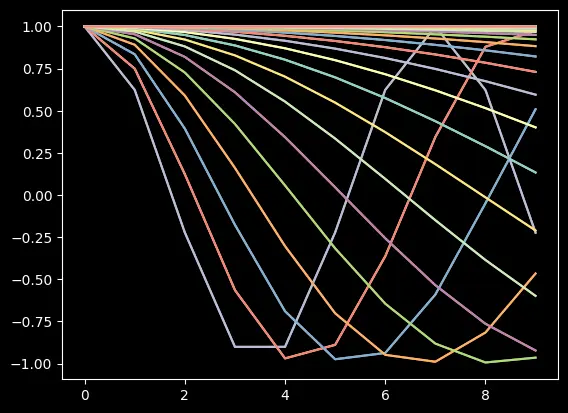
For position $p$, plane $[x_i, y_i]$ is rotated by the angle:
$$ \theta_i^{(p)} = p \times \text{inv\_freq}_i = \frac{p}{\text{base\_theta}^{2i/d}} $$- Plane $[x_1, y_1]$ rotates by a large angle (high frequency).
- Plane $[x_{d/2}, y_{d/2}]$ rotates by a small angle (low frequency).
Why does this help?
Different planes capture positional information at different scales:
| Frequency | Behavior | Encodes |
|---|---|---|
| High (early planes) | Oscillates rapidly | Fine-grained, local positional differences — distinguishes nearby tokens |
| Low (later planes) | Oscillates slowly | Coarse-grained, global positional information — distinguishes tokens far apart |
This multi-scale strategy is directly inspired by sinusoidal positional encodings from the original Transformer paper (“Attention Is All You Need”, Vaswani et al.). The key difference is that RoPE applies these frequencies as rotations (multiplicative), not as additions to the embedding. This makes RoPE compatible with the dot-product attention mechanism in a way that preserves the relative position property shown above.
Step 2: Rotation Angles
position_ids = torch.arange(0, sq_len)
freq = torch.outer(position_ids, inv_freq)
torch.outer computes the outer product of position_ids and inv_freq, producing a rotation angle for every (position, plane) pair:
For each position $p$, the frequency vector has $d/2$ entries:
$$ \left[\frac{p}{10000^{0/d}},\; \frac{p}{10000^{2/d}},\; \frac{p}{10000^{4/d}},\; \ldots,\; \frac{p}{10000^{d/d}}\right] $$The full frequency matrix across all positions is:
$$ \text{freq} = \begin{bmatrix} \frac{1}{10000^{0/d}} & \frac{1}{10000^{2/d}} & \cdots & \frac{1}{10000^{d/d}} \\ \frac{2}{10000^{0/d}} & \frac{2}{10000^{2/d}} & \cdots & \frac{2}{10000^{d/d}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{n}{10000^{0/d}} & \frac{n}{10000^{2/d}} & \cdots & \frac{n}{10000^{d/d}} \end{bmatrix} \in \mathbb{R}^{\text{seq\_len} \times d/2} $$where $d = \text{head\_dim}$.
Step 3: Query and Key Rotation
We apply cosine and sine to the frequency matrix, then concatenate them to match the full embedding dimension:
cos = freq.cos()
sin = freq.sin()
cos = torch.cat([cos, cos], dim=-1)
sin = torch.cat([sin, sin], dim=-1)
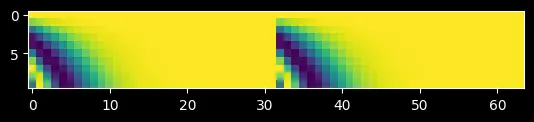
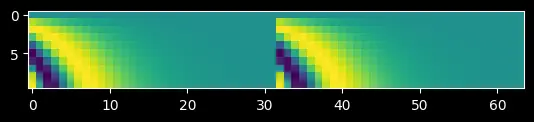
Why concatenate cos and sin twice?
The query vector has the layout $[x_1, \ldots, x_{d/2},\; y_1, \ldots, y_{d/2}]$. Both the $x$-half and the $y$-half need the same set of per-plane cosine (and sine) values. Concatenating [cos, cos] and [sin, sin] ensures every component gets the correct angle.


The rotate_half function
def rotate_half(x):
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
This rearranges $[x_1, x_2, x_3,\; y_1, y_2, y_3]$ into $[-y_1, -y_2, -y_3,\; x_1, x_2, x_3]$:
$$ \text{rotate\_half}(q) = \begin{bmatrix} -y_1 \\ -y_2 \\ -y_3 \\ x_1 \\ x_2 \\ x_3 \end{bmatrix} $$Putting it all together
Step A — element-wise multiply query by cos:
$$ \cos \times q = \begin{bmatrix} x_1\cos\theta_1 \\ x_2\cos\theta_2 \\ x_3\cos\theta_3 \\ y_1\cos\theta_1 \\ y_2\cos\theta_2 \\ y_3\cos\theta_3 \end{bmatrix} $$Step B — element-wise multiply rotate_half(q) by sin:
Step C — add them:
$$ q' = \cos \cdot q + \sin \cdot \text{rotate\_half}(q) =\begin{bmatrix} x_1\cos\theta_1 - y_1\sin\theta_1 \\ x_2\cos\theta_2 - y_2\sin\theta_2 \\ x_3\cos\theta_3 - y_3\sin\theta_3 \\ y_1\cos\theta_1 + x_1\sin\theta_1 \\ y_2\cos\theta_2 + x_2\sin\theta_2 \\ y_3\cos\theta_3 + x_3\sin\theta_3 \end{bmatrix} $$This is precisely the 2D rotation applied independently to each plane $[x_i, y_i]$ with its own angle $\theta_i$:
$$ x_i' = x_i\cos\theta_i - y_i\sin\theta_i $$$$ y_i' = x_i\sin\theta_i + y_i\cos\theta_i $$Each plane is rotated by a different angle $\theta_i$ — the planes associated with higher-frequency dimensions rotate more per position step, while lower-frequency planes rotate less. This is what gives the model a rich, multi-scale representation of position.
Step 4: Relative Rotation in Attention
After rotating both query and key, the attention dot product is:
$$ q_m^T k_n = (R(m)\,q)^T (R(n)\,k) = q^T R(m)^T R(n)\, k = q^T R(n - m)\, k $$The attention score depends only on the relative position $(n - m)$ between the query at position $m$ and the key at position $n$. This is the core property that makes RoPE a relative positional encoding, even though it is applied at the individual token level.
This relative encoding property also makes RoPE generalize well to sequence lengths longer than those seen during training. Since the model learns to attend based on relative distance, it is less sensitive to the exact absolute position values — a significant advantage over fixed absolute positional encodings, which can struggle when applied to longer contexts at inference time.
Summary
Here is a concise summary of the full RoPE pipeline:
| Step | Operation | Formula |
|---|---|---|
| 1 | Compute inverse frequencies | $\text{inv\_freq}_i = 1 / \text{base}^{2i/d}$ |
| 2 | Compute rotation angles | $\theta_i^{(p)} = p \times \text{inv\_freq}_i$ |
| 3 | Build cos/sin tables | Duplicate along last dim to cover both $x$ and $y$ halves |
| 4 | Rotate queries and keys | $q' = q \cdot \cos + \text{rotate\_half}(q) \cdot \sin$ |
| 5 | Attention score | $q_m^T k_n = q^T R(n-m)\, k$ — relative position encoded implicitly |